L'eXtensible Markup Language per gli Studi Umanistici
Roma, 17-21 maggio 2004
Gian Paolo Renello ha aperto un forum di discussione sul corso. Se avete domande, suggerimenti o critiche, potete condividerle all'indirizzo www.melammu.org, forum, XML (previa registrazione).
Per chi non fosse stato eventualmente presente all'ultima lezione, ricordo di contattarmi tramite e-lettera (per una sfortunata coincidenza sabato 22 e domenica 23 maggio è stato trasferito il mio dominio: ora però funziona regolarmente) per richiedere l'attestato di partecipazione al corso.
Ecco infine la copertina del CD!
(19/V/2004) Post-lezione 2 & 3
- Per formattare del testo in maiuscoletto, basta inserire il seguente attributo in un tag (marcatore) che contiene testo:
style="font-variant: small-caps". Se il testo che si vuole formattare non è già racchiuso in un tag (ad es. <h1>, <p>, <b>), si utilizza il tag generico <span> (che non ha alcuna funzione particolare di per sè).
- Ovviamente la tabella di caratteri ASCII (American Standard Code for Information Interchange, 1963) non fu il primo sistema di codifica dei caratteri. Lasciando da parte le crittografie, bisogna citare prima di tutto il codice Morse (1844) e quello Baudot (avete presente quelle strane macchine da scrivere a 5 tasti che si usano in parlamento??), anche se non si tratta di codifiche numeriche (cioè di sistemi che codificano i caratteri tramite numeri). Su questo argomento rimando a ASCII: American Standard Code for Information Infiltration by Tom Jennings; un esaustivo elenco storico di tabelle di codifica per caratteri (compreso vietnamita, thai, etiopico, scritture indiane) si trova anche all'indirizzo <http://homepages.cwi.nl/~dik/english/codes/stand.html>. Che ne dite di un cellulare con soli 5 tasti che usa il sistema Baudot??
- Se anche voi siete fieri giocatori del famoso gioco sudtirolese... <http://www.elamit.net/depot/boscaiola/> (ma serve solo per segnare i punti). E' un esempio di ciò che permette di fare l'uso estensivo di un linguaggio di scripting (in questo caso JavaScript, anche se il codice è poco elegante). Il grafico dei punteggi è realizzato in Vector Markup Language che è, manco a dirlo, un'applicazione XML.
- I tre meccanismi (sistema unificato di denominazione delle risorse, protocolli di trasmissione, ipertesti) attraverso i quali il World Wide Web permette la fruizione e la condivisione delle risorse: <www.w3.org/TR/html401/intro/intro.html#h-2.1>.
- L'homepage di Tim Berners-Lee.
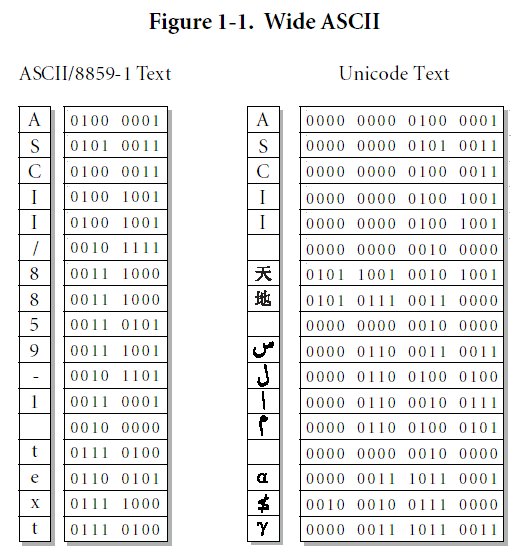
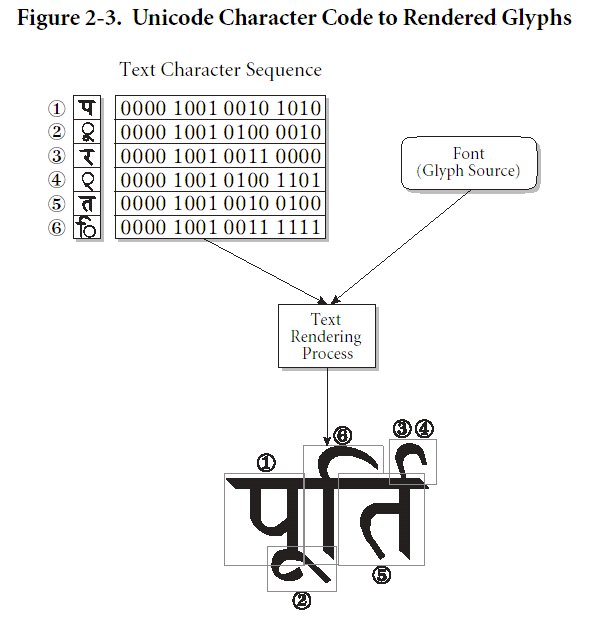
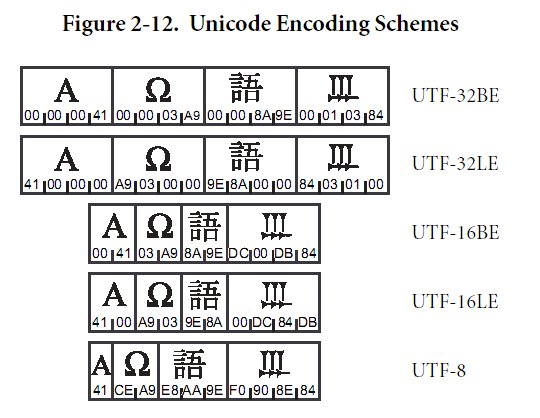
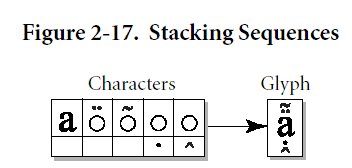
- Alcune figure a corredo di quanto detto su UNICODE (tratte dalle specifiche UNICODE):
- Lo standard UNICODE è in continua crescita (ferma restando la compatibilità con le versioni passate): sia i caratteri antico-persiani che i cunei del sillabario sumero-accadico stanno percorrendo l'iter burocratico per l'inserimento nelle future versioni dello standard (all'interno del plane 1).
- Nel definire lo standard UNICODE non è stata rivolta particolare attenzione al rapporto fra una scrittura (non latina) e la sua traslitterazione (e trascrizione) con caratteri latini (Roman in inglese) e diacritici (in risposta ad una necessità tipicamente "latinocentrica" che probabilmente andrebbe analizzata nell'ottica dello sviluppo dell'Orientalismo e degli strumenti di diffusione dell'informazione messi a punto in Europa). Su questo argomento rimando all'articolo di Bunz e Gippert, già segnalato, ma che riporto per comodità: Unicode, Ancient Languages and the WWW. Similmente, troviamo lingue come il curdo e l'osseto scritte con più scritture.
- In Windows 2000 la combinazione di tasti per visualizzare il codice UNICODE esadecimale dell'ultimo carattere battuto è
SHIFT-ALT-X! ALT-X in Windows XP. In ambedue i sistemi operativi, premendo ALT-X viene nuovamente visualizzato il glifo (così almeno dice Alan Wood).
- Risorse e strumenti segnalati nel corso della lezione senza esser riuscito a mostrarli:
- l'esaustivo elenco di Alan Wood in cui trovare fonts UNICODE in base al/i sottoinsieme/i desiderato/i. Wood segnala con precisione fonts e strumenti anche per il mondo Mac.
- Microsoft Visual Keyboard per aver sempre sott'occhio la corrispondenza fra tasti e caratteri quando si utilizza un layout di tastiera che non corrisponde a quello indicato sui vostri tasti;
- a partire da Windows 2000, è diventato possibile modificare i layouts di tastiera predefiniti grazie a Microsoft Keyboard Layout Creator (ad esempio per creare un layout per scrivere in carattere latini con determinati diacritici);
- Windows XP suddivide le scritture (scripts) in basic, complex (right to left) e east asian. Il supporto di quest'ultime due categorie va abilitato; successivamente compariranno i relativi layouts di tastiera nell'apposito elenco. In pratica Microsoft ha integrato nel sistema quelle funzioni che precedentemente dovevano essere espletate da keyboard hookers come Multikey;
- il volume Melammu Symposia III impaginato interamente in UNICODE. Nel volume degli atti del V convegno della Societas Iranologica Europaea abbiamo proposto (e istruito) agli autori di sperimentare UNICODE: al momento, il 66% di essi ha aderito al nostro invito, permettendoci di dimezzare i tempi della fase di impaginazione!
(22/V/2004) Post-lezione 7 & 8
- L'evoluzione della scrittura cuneiforme è trattata sinteticamente, ad esempio, nella già citata proposta per l'inclusione dei segni cuneiformi nello standard UNICODE.
- La pagina di un glossario di elamico achemenide con la traslitterazione di dozzine di grafie attestate per una medesima parola, in questo caso un nome di mese antico-persiano. Il fatto che si tratti di un prestito acuisce una situazione di variabilità normalmente attestate e intrinseca al carattere sillabico della scrittura cuneiforme. Per una trattazione meno semplificata, rimando a Loan-Words in Achaemenid Elamite: the Spellings of Old Persian Month-Names [lucidi].
- Il sito 3D Scanning di Adeline Lam Yan Ling (aka Adie) contiene alcune pagine che spiegano i principi di funzionamento degli scanner tridimensionali: a contatto con sonda (soprattutto per oggetti trasparenti) o tramite triangolazione ottica di una scansione laser (avete mai fatto laser-terapia? Un laser scansiona la superficie dell'oggetto proiettando una sottile linea di luce che viene ripresa da una telecamera; sapendo che la linea sarebbe diritta su una superficie piana, l'elaboratore deduce dall'aspetto filmato della linea il profilo della superficie dell'oggetto).
- Per visualizzare le tavolette virtuali dell'università di Birmingham è necessario installare un plugin VRML come Cortona VRML Client o Cosmo Player. Il Virtual Reality Modeling Language (che non è, nonostante l'ML nella sigla, un'applicazione XML (25/5/2004)) mette a disposizione delle primitive per collocare in uno spazio tridimensionale virtuale i solidi elementari. Nel caso di tavolette (la cui codifica tridimensionale non può derivare che da scansioni tridimensionali ad alta risoluzione) si deve ricorrere invece all'elemento
IndexedFaceSet, in cui è possibile dettagliare punto per punto la complessa superficie del solido. Un esempio VRML elementare.
Un approccio differente è offerto dalla tecnologia Viewpoint. Attualmente comunque il VRML (le ultime specifiche risalgono al 1997) si è evoluto nel linguaggio X3D.
- Il manuale tecnico dell'Electronic Text Corpus of Sumerian Literature (by Jarle Ebeling, Graham Cunningham, Jeremy Black) in cui viene dettagliata la derivazione dalle guidelines P4 di TEI.
- La proposta per l'inclusione della scrittura antico-persiana in UNICODE è datata al 18 settembre 1997; ovviamente quella posteriore al concepimento del CTML è quella del cuneiforme vero e proprio che è recentissima (29 gennaio 2004). Per il diverso livello di approvazione delle due proposte, rimando a Proposed New Scripts. Attualmente "under investigation" sono invece i geroglifici (Basic Egyptian Hieroglyphics) e scritture inventate come il Cirth e il Tengwar di J.R.R. Tolkien. Nel 2001 invece è stato rigettata come inappropriata nella sua formulazione la codifica del Klingon.
- Ho dimenticato di spiegare il significato di DARIOSH, trascrizione in caratteri latini del nome del re Dario in persiano moderno, che è anche una sigla: Digital Achaemenid Royal Inscription Open Schema Hypertext. Ho riportato più sotto il materiale illustrativo presentato a lezione. Aggiungo solo che, nelle trasformazioni XSL, le evidenziazioni in giallo sono ottenute tramite un linguaggio di scripting, Javascript.
- L'esempio finale dedicato alle virgolette era ovviamente una banalizzazione dei vari usi, più o meno corretti, che si fa delle virgolette. La frase n. 3 è tratta dal materiale didattico messo a disposizione dopo la lezione Quando l'Elamico si chiamava 'Scitico'; la frase n. 4 di François Vallat (datata 21/06/1995) dalla nota ‘Šutruk-Nahunte, Šutur-Nahunte et l'imbroglio néo-élamite’ nel periodico Nouvelles Assyriologiques brèves et utilitaires, 1995/46; la frase n. 5 da J.R.R. Tolkien, The Lord of the Rings, The Fellowship of the Ring, chapter 1 (liberamente adattata).
Cuneiform Text Markup Language
(22/V/2004) Il materiale presentato è stato estratto dalla brochure illustrativa (bozza del 28 maggio 2003) del progetto DARIOSH (Digital Achaemenid Royal Inscription Open Schema Hypertext). Il progetto è una collaborazione fra l'Istituto Italiano per l'Africa e l'Oriente (IsIAO) e il Museo Archeologico Nazionale d'Iran, Tehran. Il gruppo di lavoro italiano è composto da Adriano Valerio Rossi, Grazia Giovinazzo (Università “L’Orientale” di Napoli), Ela Filippone (Università della Tuscia di Viterbo) e dai relatori del corso.
Per un testo cuneiforme, il CTML si ripropone di codificare le seguenti tipologie di informazioni, indicandone le molteplici interrelazioni esistenti:
- Dati archeologici, che possono essere suddivisi sommariamente in due categorie:
- dati di localizzazione, consistenti in informazioni riguardo i luoghi di ritrovamento, ovvero tanto il contesto antico in cui le iscrizioni erano collocate quanto il contesto stratigrafico in cui in epoca moderna o contemporanea sono state ritrovate, nonché il loro attuale luogo di conservazione;
- la descrizione fisica, consistente in informazioni riguardanti i manufatti iscritti e il loro attuale stato di conservazione.
- Dati paleografici ed epigrafici, ovvero informazioni sugli antichi sistemi di scrittura e i grafemi usati.
- Dati testuali, ovvero traslitterazioni segno per segno, trascrizioni normalizzate, analisi grammaticali, traduzioni in lingue moderne, note e commentari.
- Dati lessicali e linguistici, ovvero glossari e lessici, descrizioni fonologiche, morfologiche e sintattiche.
- Bibliografie, ovvero riferimenti alla letteratura primaria e secondaria.
Schemi XML
Gli schemi XML definiscono le regole con cui sono registrati i dati. Stabiliscono inoltre quali tipi di informazioni devono essere archiviate e la struttura in cui devono essere organizzate. Sono stati sviluppati tre schemi strettamente interrelati ma indipendenti. La configurazione modulare risultante si è rivelata estremamente semplice e estensibile. Questi sono i dati gestiti da ciascuno schema:
- metadati testuali, come il nome convenzionale e l’abbreviazione di una fonte testuale antica, la dettagliata descrizione fisica di ciascun esemplare con indicazioni sul luogo di ritrovamento e la collocazione attuale, i riferimenti bibliografici a edizioni, traduzioni e materiale iconografico correlato. Questo schema definisce il Textual Metadata Markup Language (TMML);
- traslitterazione e traduzione di un testo antico con annotazioni paleografiche e commentario testuale. Questo schema definisce il Cuneiform Text Markup Language (CTML) in senso stretto;
- descrizione di risorse, specialmente riferimenti bibliografici. Questo schema definisce il Bibliographical Resource Markup Language (BRML).
Cuneiform Text Markup Language
Il Cuneiform Text Markup Language è un formato XML di marcatura testuale sviluppato al fine di scambiare testi cuneiformi traslitterati, trascritti, tradotti e commentati attraverso il web. Fornisce inoltro il supporto per incorporare testo cuneiforme entro articoli di carattere scientifico con note a piè di pagina e bibliografia.
Al fine di prevenire qualsiasi eventuale confusione di caratteri e segni diacritici, i dati sono codificati secondo lo standard UNICODE. Riferimenti a tali caratteri avverrano tramite entità, ad esempio “&along;” per ā o “θ” per θ e così via. Fogli di entità distinti si adatteranno a differenti rappresentazioni visuali dei caratteri diacritici, ad esempio š come sh nei vecchi sistemi privi di supporto UNICODE. E’ inoltre possibile preparare nuovi fogli di entità per rispondere a esigenze personalizzate conformi alla pratica di ciascun utente, ad esempio aleph al posto di a nella traslitterazione dell’antico persiano di W. Hinz.
Il CTML è composto da tre elementi principali: DIV, LOG e NOTE. L’intento primario del linguaggio è la definizione di pochi elementi di base riutilizzabili poi coerentemente in contesti differenti. Questo significa che per i testi complessi si può raggiungere un alto livello di precisione, mantenendo semplice allo stesso tempo la codifica di testi privi di informazioni dettagliate. La complessità della codifica rimane quindi sempre proporzionale alla complessità dei dati.
Gli elementi DIV rappresentano le suddivisioni fisiche di un testo cuneiforme, come le facce di una tavoletta o le colonne e le linee in cui è disposto il testo. Ogni elemento DIV può contenere altri elementi DIV o una sequenza di elementi S. Ogni elemento S rappresenta un segno grafico e può contenere sia dati paleografici come altezza, larghezza e spaziatura sia informazioni correlate alla leggibilità e allo stato di conservazione. Al fine di formare un apparato critico, gli elementi S possono essere racchiusi in elementi APP contenenti una o più letture divergenti del testo. Queste possono rappresentare sia opinioni differenti da studioso a studioso sia testimoni discordanti del testo stesso.
Gli elementi LOG rappresentano la struttura logica di un testo. Ogni elemento LOG può contenere o altri elementi LOG o la trascrizione (normalizzazione) del correlato frammento testuale. Gli elementi LOG possono marcare periodi, frasi, sintagmi, parole e anche affissi morfologici. Gli attributi forniscono pieno supporto per l’analisi grammaticale e sintattica. Inoltre è possibile segnalare nomi propri, divini, geografici etc., o assegnare speciali categorie di significato o funzione. L’elemento APP si comporta con LOG in modo simile a S. Anche la traduzione di un testo può essere marcata con elementi LOG in modo da correlare periodi, frasi e parole fra una fonte antica e la sua traduzione moderna. Un meccanismo simile sincronizza le versioni in lingue differenti di uno stesso testo. L’elemento LOG è estremamente versatile, tanto da poter correlare un suffisso o un sintagma preposizionale babilonese con una singola parola antico persiana.
Gli elementi NOTE contengono annotazioni e commenti con supporto di testo formattato (cioè corsivo, grassetto etc.). E’ inoltre possibile incorporare testo cuneiforme, riferimenti a fonti testuali e rimandi bibliografici che possono poi essere automaticamente indicizzati. Ogni elemento NOTE può essere correlato con uno o più elementi DIV, S, APP o LOG, strutturando così le annotazioni conformemente a ciò cui sono correlate, ad esempio note di paleografia, commentario testuale, problemi di traduzione, etc.
Glossari globali o selettivi con analisi grammaticale, indici di nomi propri o geografici, liste di occorrenze di segni, indici di fonti o rimandi bibliografici citati, possono essere creati istantaneamente attraverso appropriate trasformazioni XSLT. I singoli lemmi possono essere riordinati in ogni momento secondo l’ordine alfabetico, il numero del segno nei sillabari, la classe grammaticale etc. senza ricaricare la trasformazione. Allo stesso modo possono essere eseguite ricerche e analisi statistiche altamente dettagliate.
Bibliographic Resource Markup Language
Il Bibliographic Resource Markup Language è strutturato a partire dall’elemento REF.
Gli elementi REF sono riferimenti bibliografici a libri, articoli, oppure anche a testi e database disponibili on-line. Questo elemento è estremamente versatile, cosicché è possibile rimandare sia a una singola tavoletta che a un corpus di testi. Può contenere inoltre una descrizione fisica del libro o del manufatto iscritto, oltre a dati di localizzazione come, ad esempio, la reperibilità di un determinato libro in una particolare biblioteca o il luogo attuale di conservazione di una tavoletta. Inoltre può registrare informazioni dettagliate sugli autori: note biografiche, istituzione di appartenenza, indirizzo di posta ordinaria ed elettronica, homepage, eventualmente una o più fotografie.
Strumenti
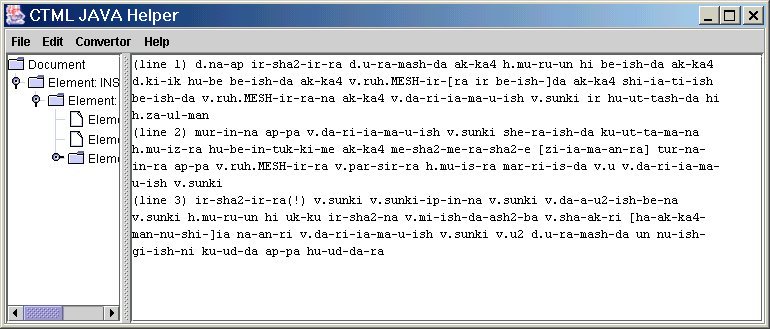
JAVA Data Entry Helper (JDEH) e Cuneiform Parser (JCP)
L’applicazione JAVA Data Entry Helper (programma di aiuto in JAVA per l’input dei dati) dal lato utente è costituita da un’interfaccia user friendly che gestisce la creazione e la modifica di files TMML, CTML e BRML, risparmiando all’utente la noiosa compilazione del formato grezzo XML. Il JDEH è in effetti un potente analizzatore di testo cuneiforme e un sistema di generazione automatizzata di files XML.
Queste sono le linee che ne hanno guidato la realizzazione:
- la scelta di JAVA come linguaggio di programmazione per lo sviluppo di un’applicazio-ne platform-independent che, in quanto tale, può essere ese-guita su qualsiasi computer e con qualsiasi sistema operativo;
- l’implementazione di uno strumento semplice e intuitivo per l’inserimento dei dati, perché rispecchia nella sua impostazione un diffuso editor di testo come Windows Notepad.
Lo spazio di lavoro dell’applicazione è stato suddiviso verticalmente in due parti.
Nell’area principale posta sulla destra, l’utente può digitare o incollare la traslitterazione di un testo cuneiforme utilizzando le più diverse convenzioni di scrittura (ad esempio sh per š, il punto che indica un determinativo altrimenti posto in apice, le parentesi quadre che racchiudono segni ricostruiti o poco leggibili, etc.). L’analizzatore interno, il JAVA Cuneiform Parser, “traduce” questo testo in elementi DIV, S e LOG conformemente allo schema CTML. L’analizzatore è collegato con il Cuneiform Syllabary Database che provvede una grande quantità di informazioni per ognuno dei segni riconosciuti.
L’area a sinistra riproduce in una struttura gerarchica ad albero gli elementi correlati secondo lo schema TMML. Selezionando con il mouse uno degli elementi, l’utente ne può modificare facilmente i valori e gli attributi. I nodi dell’albero possono essere espansi o compressi quando si ha a che fare con grandi quantità di dati. Nuovi elementi (come ad esempio un ulteriore riferimento bibliografico) possono essere aggiunti su richiesta dell’utente.
Selezionando il commando “salva” o “salva con nome” dal menù, il JAVA Data Entry Helper salva i dati in formato XML, mantenendo anche una copia di backup del testo grezzo cuneiforme. Files XML esistenti possono essere aperti per ulteriori modifiche.
Cuneiform Syllabary Database (CSDB)
Il Cuneiform Syllabary Database contiene informazioni dettagliate per ciascun valore attestato nella scrittura cuneiforme accadica ed elamica. Dando la lettura di un segno, il database fornisce informazioni quali le lingue e i periodi in cui era utilizzato e l’eventuale uso come logogramma o determinativo. Collegandosi a questo database il JAVA Cuneiform Parser può inoltre riconoscere la lingua che sta analizzando senza alcun bisogno di indicazioni esplicite da parte dell’utente.
Il database contiene anche una tabella estensibile con informazioni sulle convenzioni di scrittura dei segni diacritici e di caratteri speciali. I dati estratti dal database sono incorporati nel file CTML in modo da evitare ulteriori connessioni al database, rendendo agevole l’interscambio dei testi cuneiformi.
Alcuni esempi di trasformazione XSL dei dati
Gli esempi presentati sono stati creati automaticamente applicando diverse trasformazioni XSLT ad un unico file di dati, dsab.xml, ottenuto inserendo nel JAVA Data Entry Helper il testo grezzo dell’iscrizione trilingue della statua di Dario ritrovata a Susa (DSab). Prima di applicare le trasformazioni, e lavorando sempre nel JAVA Data Entry Helper, è stata effettuata l’analisi sintattica e grammaticale. Man mano che la base di dati aumenta, il JAVA Data Entry Helper potrà dedurre l’analisi grammaticale cercando riscontri nei testi già codificati.
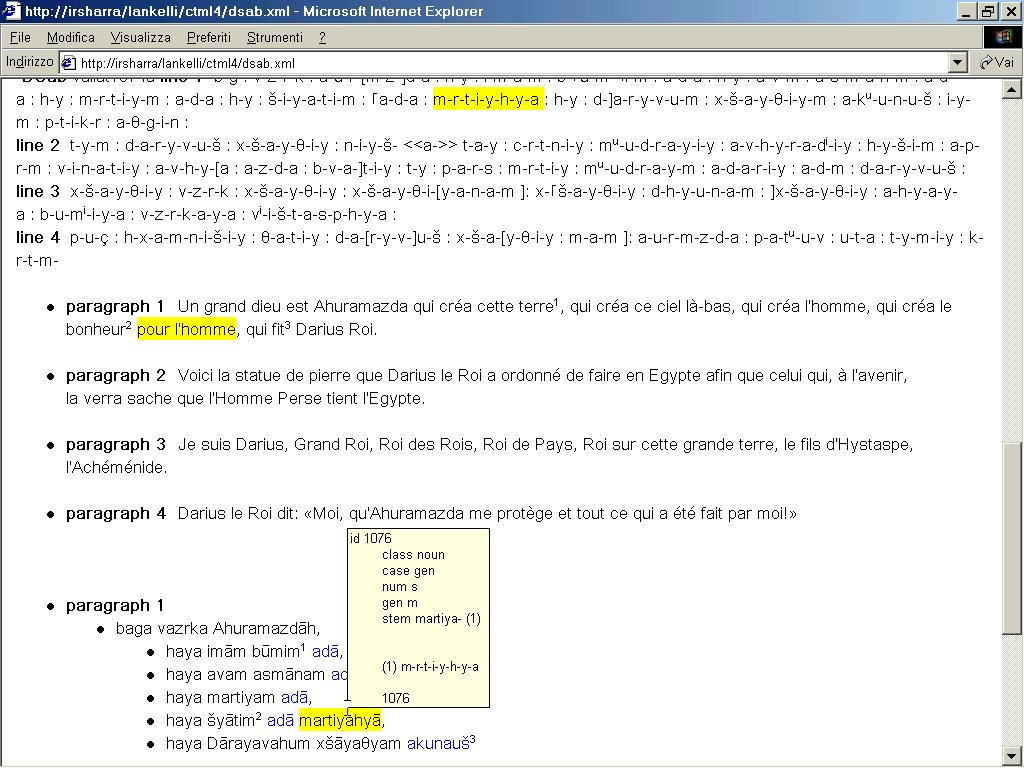
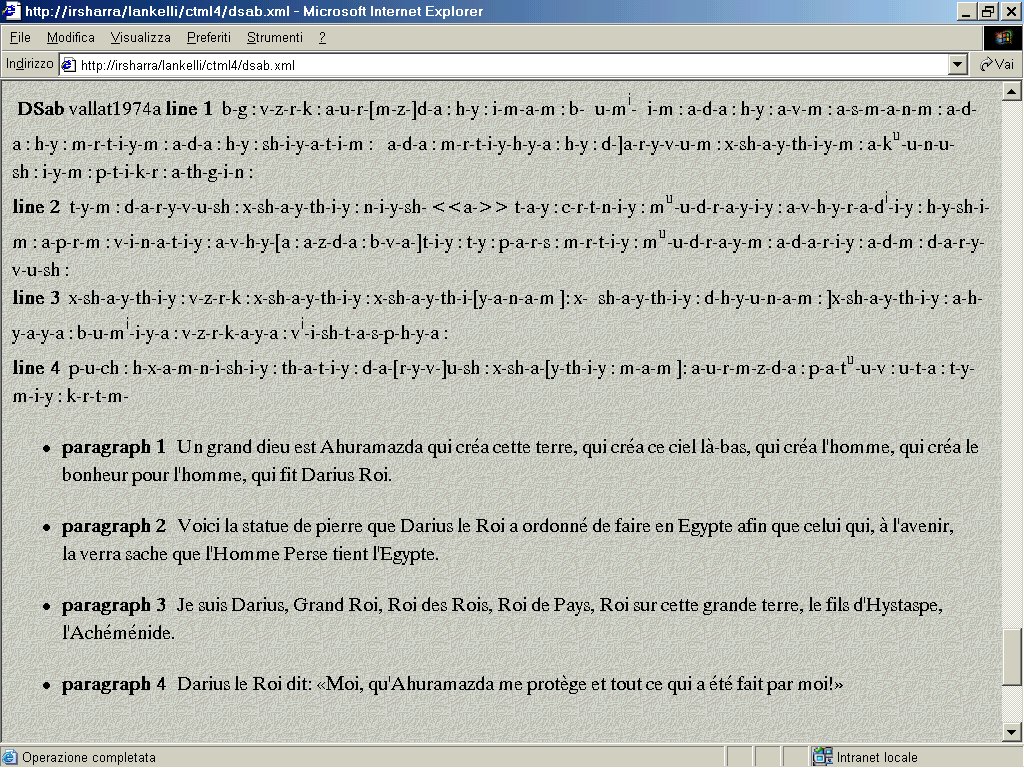
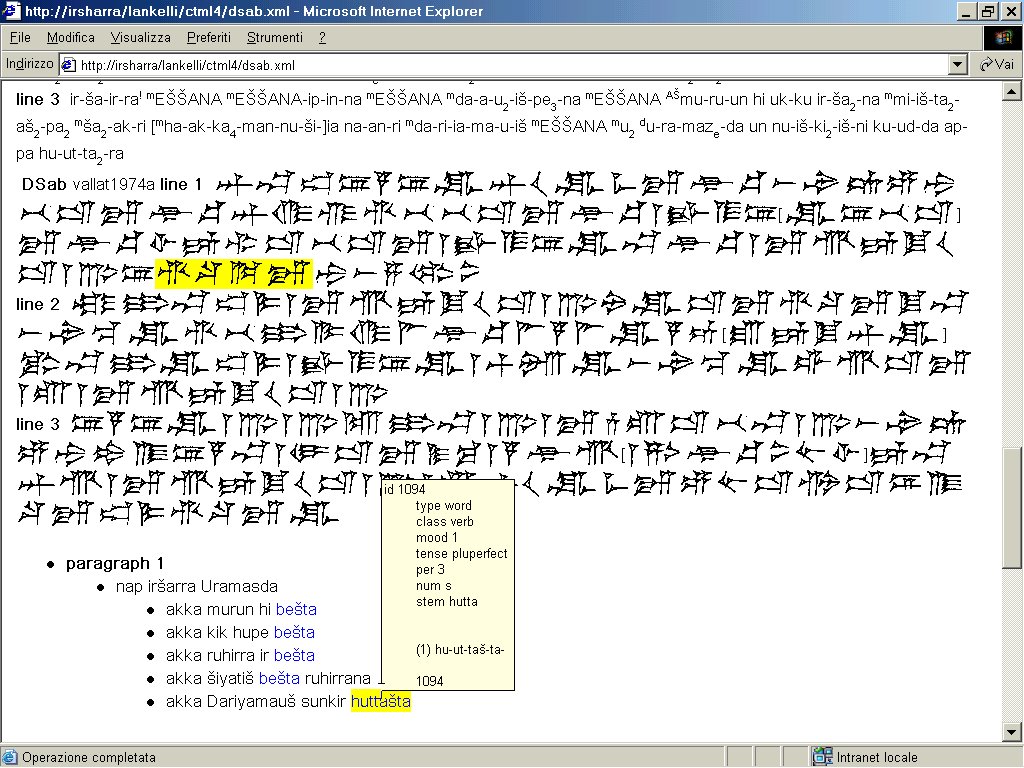
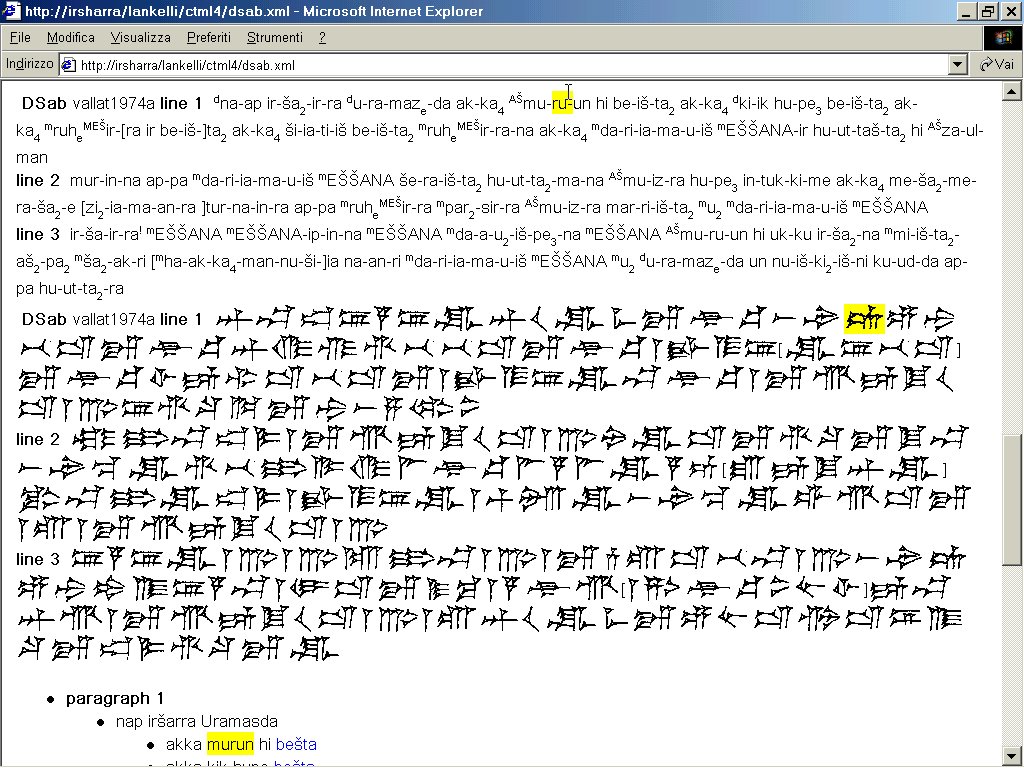
- XSLT 1 Immagine che mostra le interrelazioni fra fotografia, testo cuneiforme e traduzione, indicate da un’evidenziazione in giallo al passaggio del puntatore su qualsiasi elemento testuale.
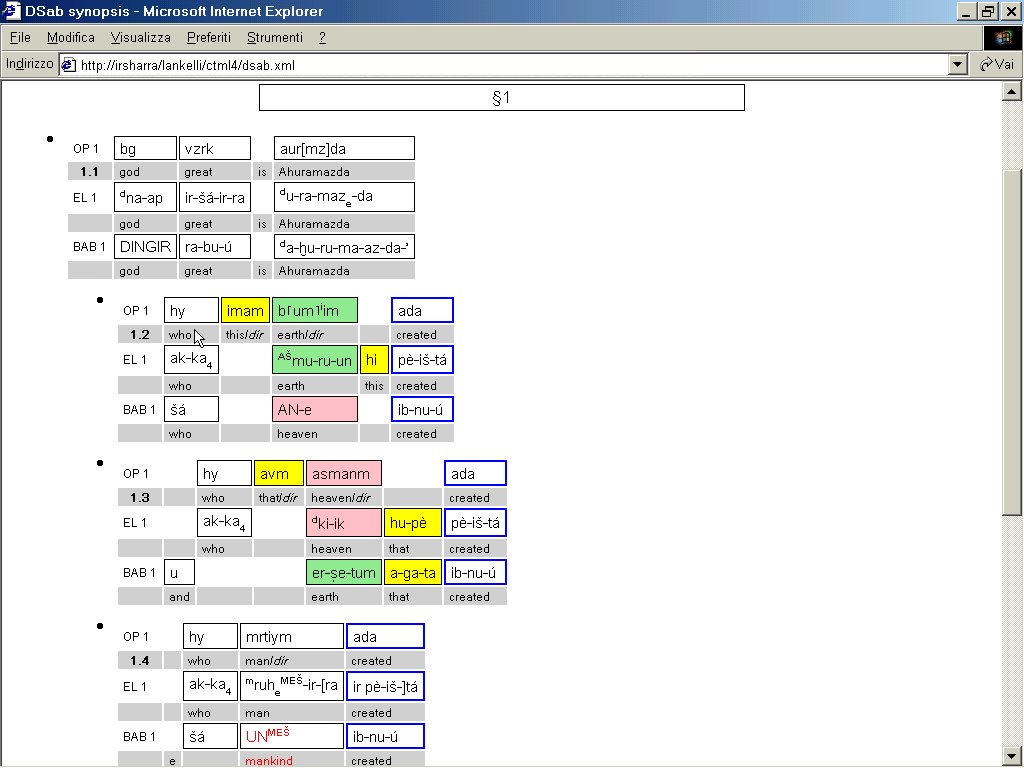
- XSLT 2 Immagine che mostra la sinossi delle versioni antico persiana, elamita e babilonese di DSab così come ci sono pervenute. In essa è visibile l’ordine sintagmatico di ciascuna versione. I sintagmi semanticamente affini sono incolonnati. Nel caso in cui l’ordine sintagmatico fra le diverse lingue fosse divergente, a sintagmi semanticamente affini corrisponde identica colorazione. E’ peraltro possibile estrapolare visivamente anche altri tipi di informazione. In questa dimostrazione, a titolo di esempio, sono stati bordati di blu tutti i sintagmi verbali. Ogni punto sulla sinistra marca una frase; frasi subordinate sono rientrate. o iconografico.
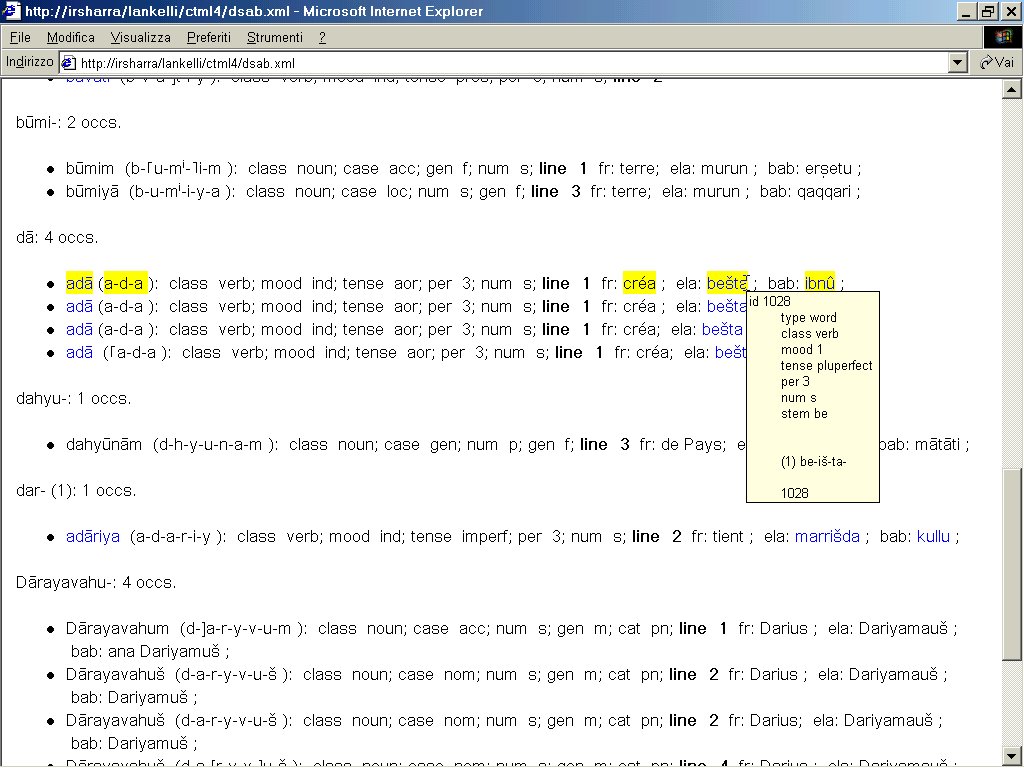
- XSLT 3 Immagine che mostra l’analisi grammaticale che appare a video al passaggio del puntatore su una parola.
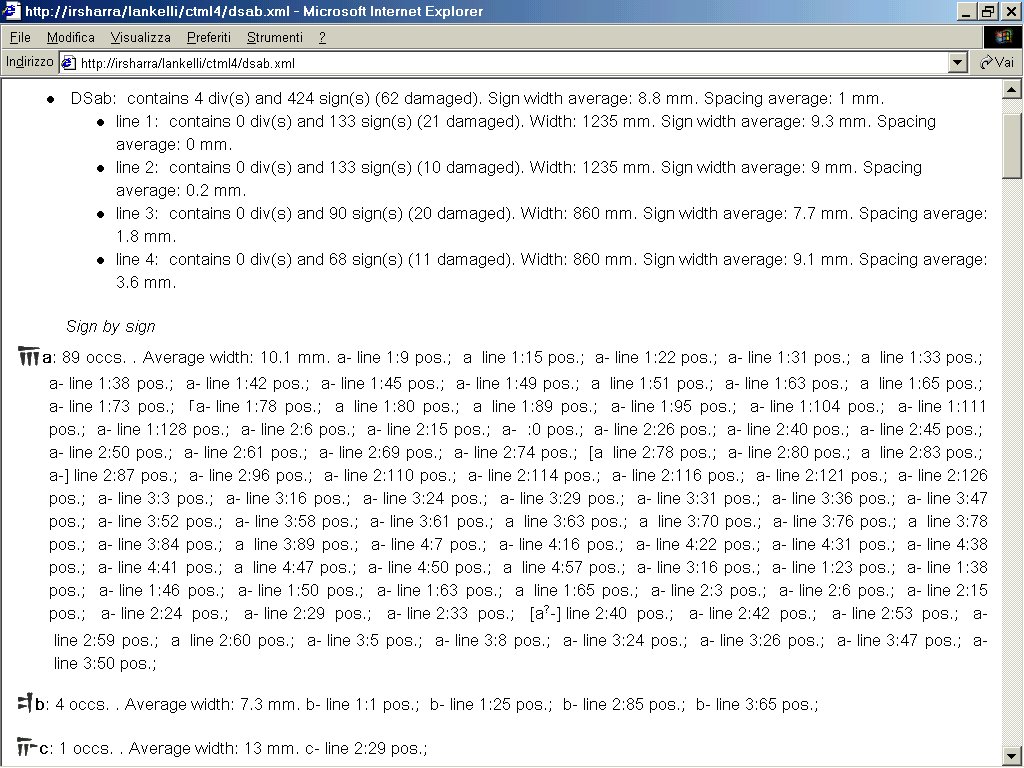
- XSLT 4 Immagine che mostra un riepilogo delle informazioni paleografiche seguite da un trattamento dettagliato segno per segno. La lista dei segni può essere riordinata in ogni momento in base al numero d’ordine del segno nei sillabari, la sua designazione o al numero di occorrenze, senza dover ricaricare la visualizzazione della pagina. Inoltre le letture corrispondenti al segno selezionato vengono evidenziate nel testo dell’iscrizione.
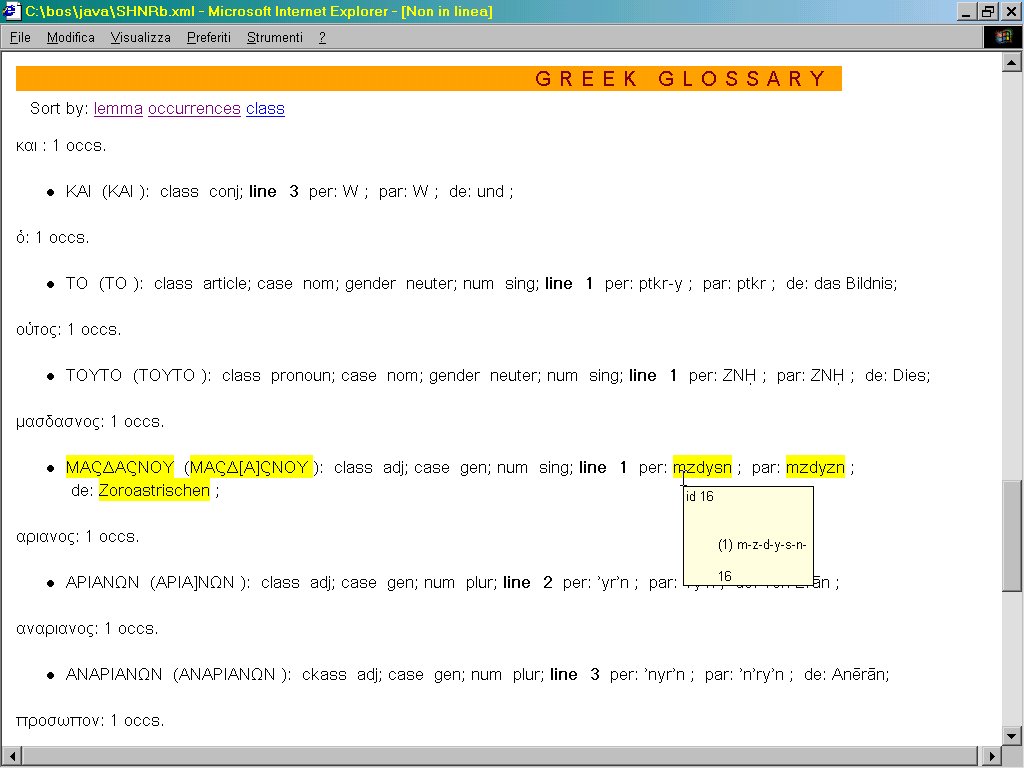
- XSLT 5 Immagine che mostra il glossario della versione antico persiana di DSab. Per ogni lemma sono elencati l’analisi morfologica, la traduzione e le parole corrispondenti nelle altre versioni. Il glossario può essere riordinato in ogni momento in base all’ordine alfabetico, alla classe grammaticale o al numero di attestazioni senza dover ricaricare la visualizzazione della pagina.
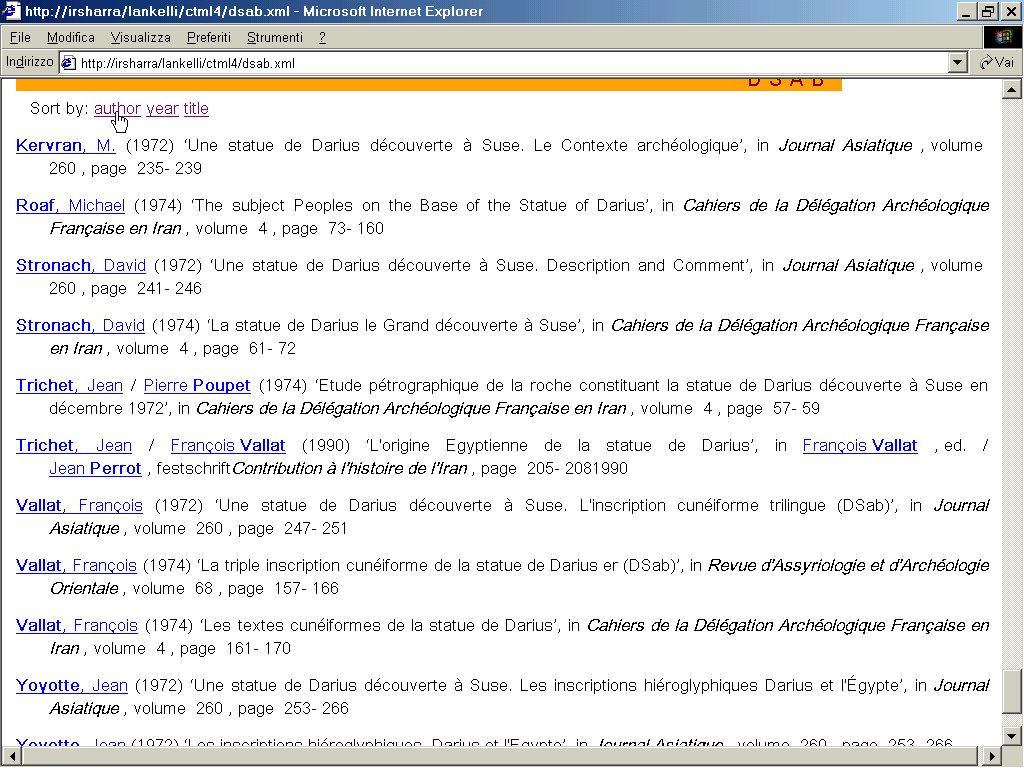
- XSLT 6 Immagine che mostra una bibliografia di base per DSab. Le referenze bibliografiche possono essere riordinate in ogni momento in base al titolo, all’autore o all’anno di pubblicazione senza dover ricaricare la visualizzazione della pagina.
- XSLT 7Immagine che riflette la sostituzione dei sottostanti fogli di entità e CSS. Sono cambiati la rappresentazione dei segni diacritici e l’aspetto grafico della pagina.
- XSLT 8
- XSLT 9
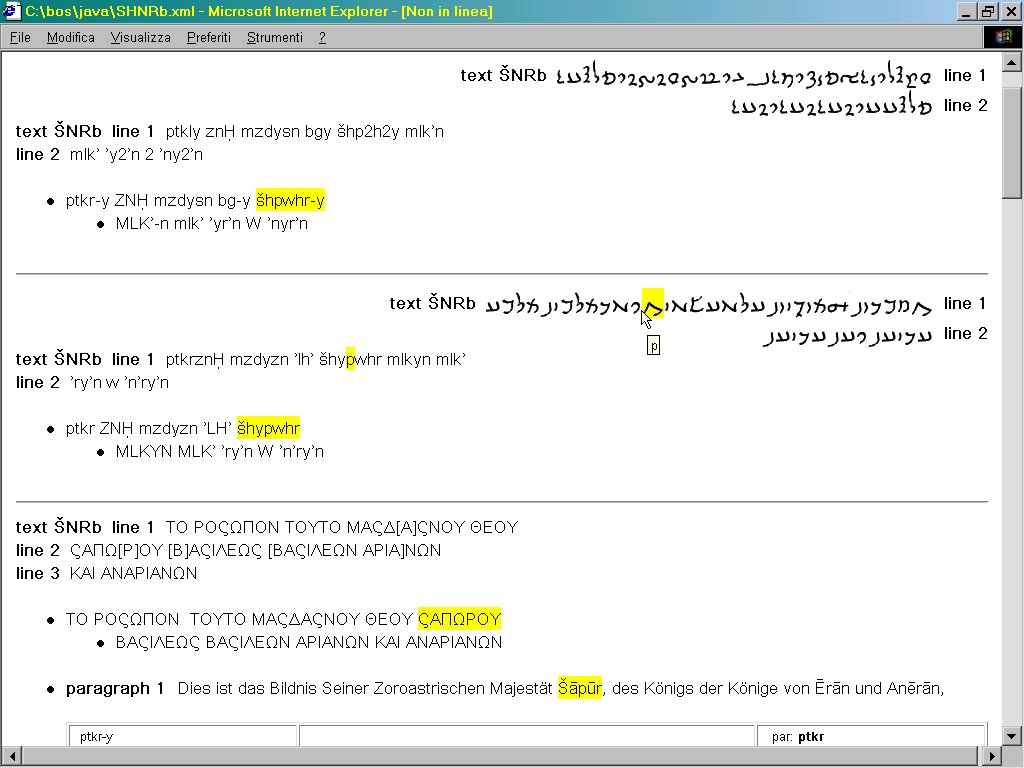
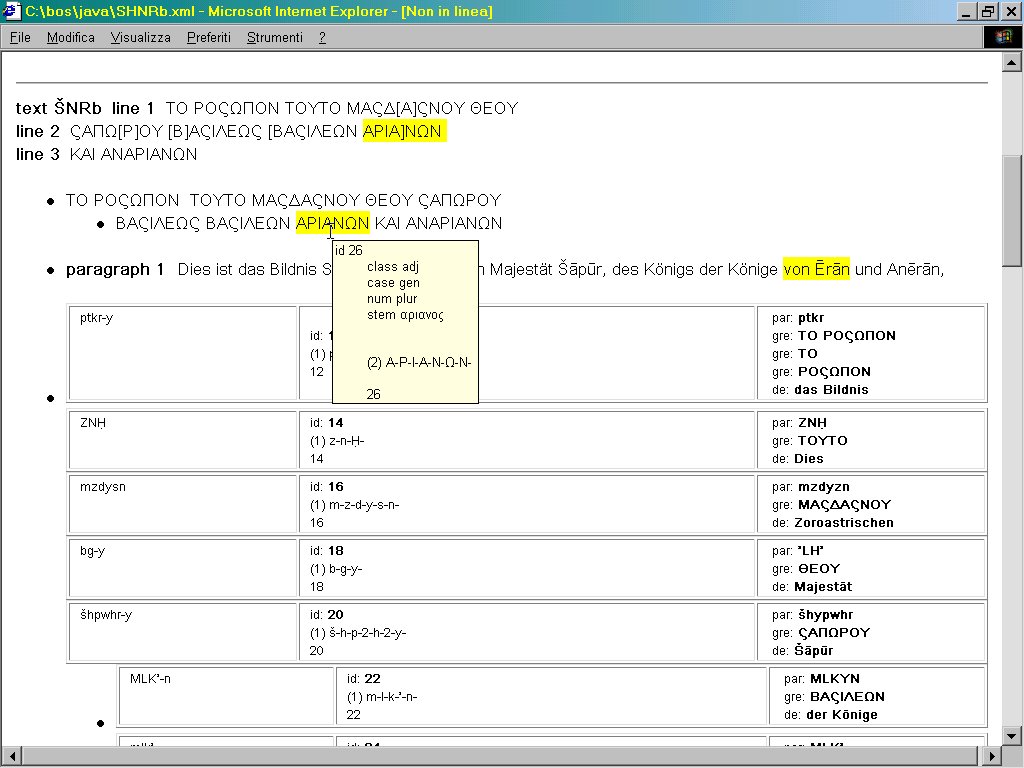
Esempi di trasformazione XSL applicati ad un'iscrizione trilingue sassanide
L'iscrizione codificata è quella di Šapur I (241-272 d.C.) a Naqš-e Rustam. Il testo è stato tratto da:
Michael Back (1978) Die Sassanidischen Staatsinschriften: Studien zur Ortographie und Phonologie des Mittelpersischen der Inschriften zusammen mit einem etymologischen Index des mittelpersischen Wortgutes und einem Textcorpus der behandelten Inschriften (Acta Iranica. Encyclopédie permanente des études iraniennes, volume 18), Téhéran-Liège.
Il CD-rom
Il CD-rom contiene materiale liberamente scaricabile dalla rete. Tuttavia va inteso come destinato ad uso esclusivamente personale dei partecipanti al corso.
| xml_course.pdf | Il depliant del corso. |
| encoding.htm | Iniziative per la codifica digitale di testi antichi. Cliccando sui collegamenti [CDrom] viene visualizzato il materiale incluso nel CD-rom all'interno delle seguenti cartelle. |
| links.htm | Collegamenti a siti riguardanti il Vicino Oriente antico con due ampie sezioni dedicate alle risorse bibliografiche e agli strumenti UNICODE. Cliccando sui collegamenti [CDrom] viene visualizzato il materiale già incluso nel CD-rom all'interno delle seguenti cartelle. |
| \articles | Articoli relativi alla codifica digitale dei testi cuneiformi. Contiene anche due cartelle sulla storia del World Wide Web e di HTML. |
| \courses | Tre corsi XML e un manuale di riferimento HTML in formato elettronico. |
| \examples | Gli esempi HTML, XML e XSLT presentati durante il corso. I files bibliography.htm, ctml.css, bibliography.xml e brml.xsl mostrano in azione le diverse caratteristiche dei rispettivi linguaggi e sono stati composti appositamente per essere studiati. |
| \fonts | Alcuni fonts UNICODE fra cui Arial UNICODE MS (arialuni.ttf) e Titus Cyberbit Basic (tituscbz.ttf). Per installare i fonts, una volta scompattato l'eventuale archivio, selezionare "Tipi di carattere" nel "Pannello di controllo" di Windows. |
| \iso690 | Lo standard ISO-690 per i riferimenti bibliografici. |
| \micorsoft_internationalization | Alcune pagine dal sito Internet della Microsoft riguardanti l'internazionalizzazione del sistema operativo Windows. |
| \mirrors | Replica off-line di diversi siti fra cui UNICODE, le risorse UNICODE di Alan Wood, TEI, XStar e OSIS. Si possono consultare cliccando sul relativo file .tpp dopo aver installato il software Teleport (utilizzato per scaricarli dalla rete; il programma di installazione è nella cartella \software) oppure ricercando nelle varie cartelle il file index.htm(l). Per motivi di spazio, alcune sezioni dei suddetti siti ritenute meno rilevanti sono state rimosse. |
| \software | Il materiale è suddiviso in quattro cartelle corrispondenti alle seguenti categorie: software bibliografico (End Note, Pro Cite, Biblio Express), editors UNICODE (EmEditor, UniPad, UniEdit e altri), editors XML (XMLspy, Peter XML Editor e molti altri), keyboard hookers (MultiKey, Keyman, Aksharamala per le scritture indiane, Microsoft Visual Keyboard, Microsoft Keyboard Layout Creator). UniPad e UniEdit utilizzano un font UNICODE standard interno e visualizzano quindi sempre correttamente il testo. Antioch (keyboard hooker per scrivere in greco ed ebraico) e Classical Text Editor (CTE, editor per edizioni critiche) si trovano nelle cartelle dei relativi siti Internet in \mirrors. |
| \w3c_specifications | La documentazione ufficiale del World Wide Web Consortium relativa a HTML, CSS, DOM, XML, XML Schema, XSLT, XLink (incluso XPath). |
©2000-2004 Copyright by Gian Pietro Basello, Stefano Buscherini & Gian Paolo Renello
ElamIT.net <www.elamit.net> (old URL: http://digilander.libero.it/elam)
Write to <elam@elamit.net>
Napoli, 11/V/2004; Persiceto, 14/V/2004; Napoli, 22/V/2004
Il materiale (testi e immagini) contenuto in questo sito può essere liberamente utilizzato per fini personali, didattici, non commerciali. Non può essere riprodotto senza indicarne correttamente l'autore e l'indirizzo internet (URL). Sarà gradita la segnalazione a <elam@elamit.net> di ogni uso o collegamento al materiale contenuto in questo sito. Grazie!
The contents of this site, including all images and text, are for personal, educational, non-commercial use only. The contents of this site may not be reproduced in any form without proper reference to Author and Internet Address (URL). Please report to <elam@elamit.net> every use or link to these contents. Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}